Sample Relationships
Dictionary v3.0.0 Documentation v2.1.0
Context
To fully interpret the measures coming out of samples, it is sometimes helpful to know how they are related to each other. For example, two samples taken at the same site, at the same time, with the same method, can be used to characterize the variability inherent to the sampling strategy or sampling matrix. When samples are composited from several subsamples, it is useful to know which subsamples were used and where they came frame. Conversely, it is also helpful to know what pooled samples are related to a given subsample. Parts of samples can also be spiked with a viral target as part of a quality assurance protocol. Keeping a trace of the relationships linking various samples supports the retrieval of related samples inside the PHES-ODM database and thus improves the interpretability of the data.
Modelling sample relationships
There are several ways in which samples can be related.
Samples can be related via:
- The splitting of an original sample
- A subsample is related to its parent sample (
child). - A sample split at the sampling location yields field replicates who are related to each other (
fieldReplicate). - A field sample is related to a sample generated from it in the laboratory (
labDuplicate). - Two samples collected at the same time and place are related to each other (
colocated). - A field sample is related to a control sample processed alongside it (
control). - A field sample is related to a subsample that has been modified as part of a general quality control procedure (
lcsd), or as part of a recovery efficiency protocol (msd).
- A subsample is related to its parent sample (
- The combination of several samples
- Parent samples related to the final pooled sample (
pooled).
- Parent samples related to the final pooled sample (
Example of sample relationship webs are found in Figure A.
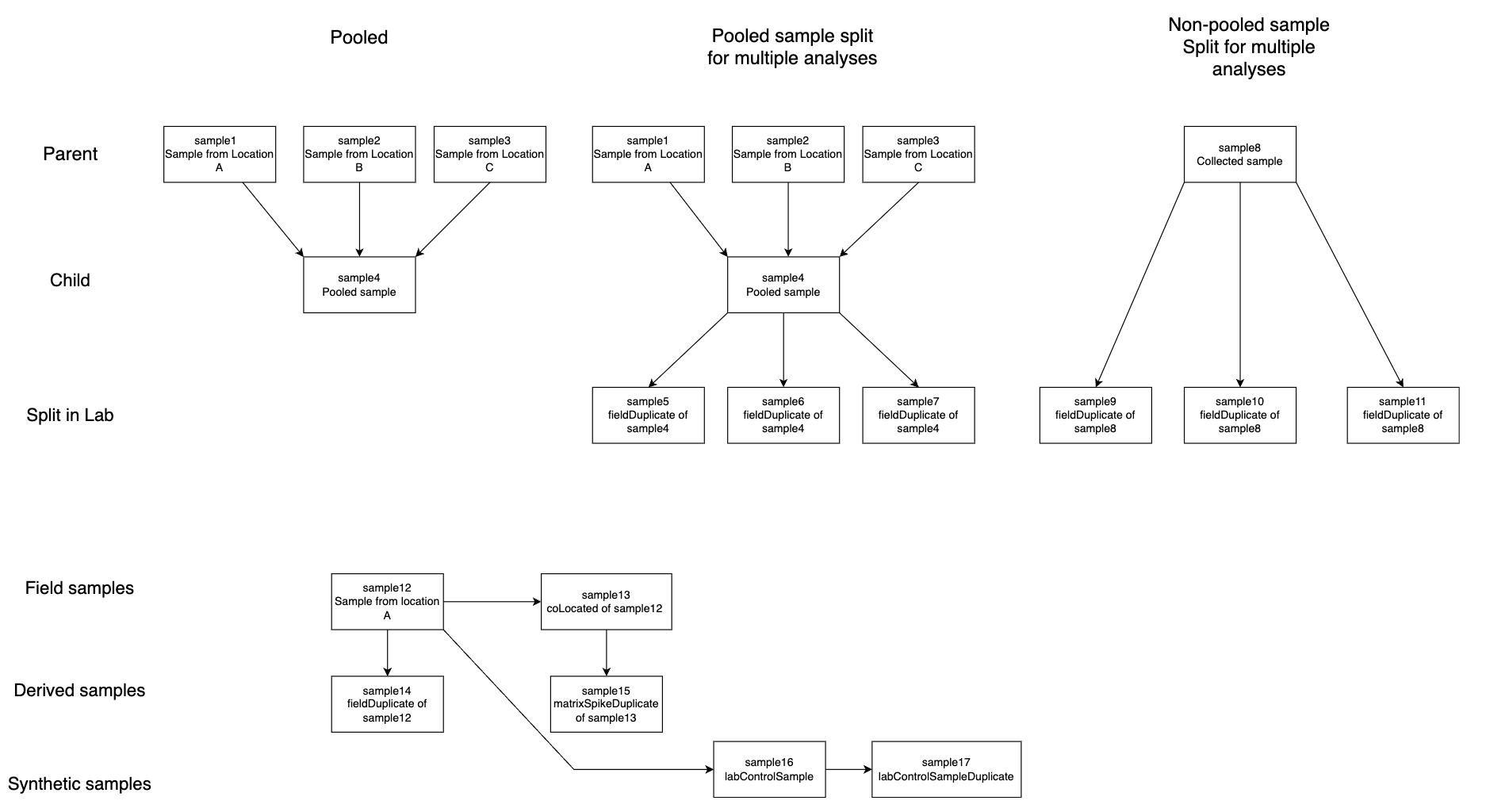
Because a single sample can be related to many others, efficiently storing both the sample information (recorded in samples) and that sample’s relationships to other samples in a single database table is impossible. This realization led to the creation of the separate sampleRelationships table in the PHES-ODM.
Implementation
The SampleRelationships table is responsible for linking samples with each other and for defining the nature of the relationships. Each row defines a relationship. A sample can have any number of relationships to other samples. The table implements four attributes:
sampleRelationshipsIDsampleIDSubjectrelationshipIDsampleIDObject
Where sampleRelationshipsID exists as a primary key and unique reference for each row, while the remaining attributes of each row can be read as a sentence of the form:
[sampleIDSubject] is a [relationshipID] of [sampleIDObject]The acceptable values for relationshipID are the following at the moment, though some more could be added to the dictionary of the need arises: (to request an new part to be added to the PHES-ODM, create a new issue on the GitHub repository, or fill out this Google Form)
- child
- colocated
- fieldReplicate
- msd
- labDuplicate
- lcsd
- controlTo complete the picture presented by the sampleRelationships table, one can read the attributes in the samples table that describe the sample’s nature:
repType(replicate type) indicates what kind of replicate a sample is (field replicate, matrix spike replicate, lab control replicate, etc. - see replicateSet for the full list).pooledindicates if the sample is the result of the combination of several samples. It is important to note thatpooledis a transitive property: subsamples derived from apooledsample are alsopooled. This is a boolean variable, carrying either TRUE or FALSE as possible values.
Below are two examples of possible relationship webs between samples and the the resulting entries in a sampleRelationships table.
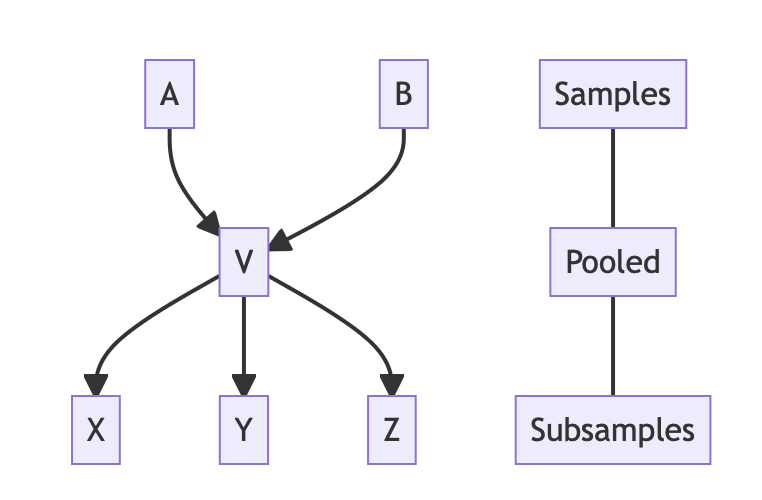
| sampleIsSubject | relationshipID | sampleIsObject |
|---|---|---|
| V | child | A |
| V | child | B |
| X | child | V |
| Y | child | V |
| Z | child | V |
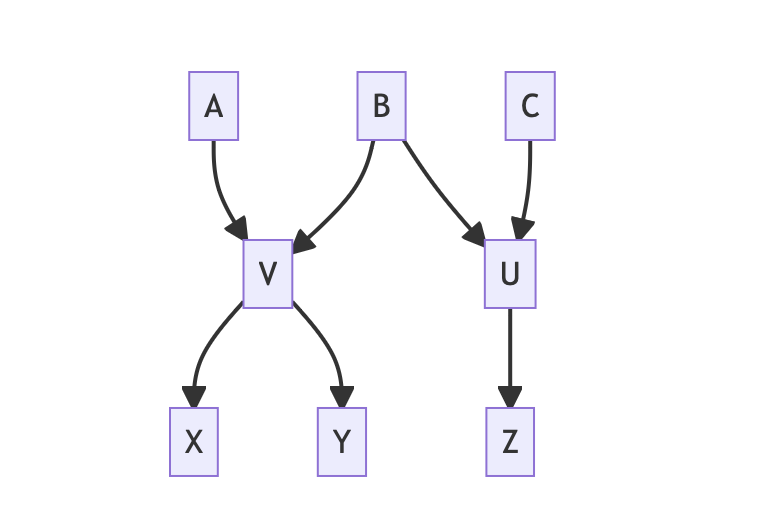
| sampleIsSubject | relationshipID | sampleIsObject |
|---|---|---|
| V | child | A |
| V | child | B |
| U | child | B |
| U | child | C |
| X | child | V |
| Y | child | V |
| Z | child | U |